wget has been incapable of properly mirror this site, so I looked into the alternatives that can do this task properly.
Problem
With dozens of attempt of modifying the parameter of the GNU wget command, I eventually gave up.
After a little investigation, I found that the image is fetch dynamically as I scroll down the page. 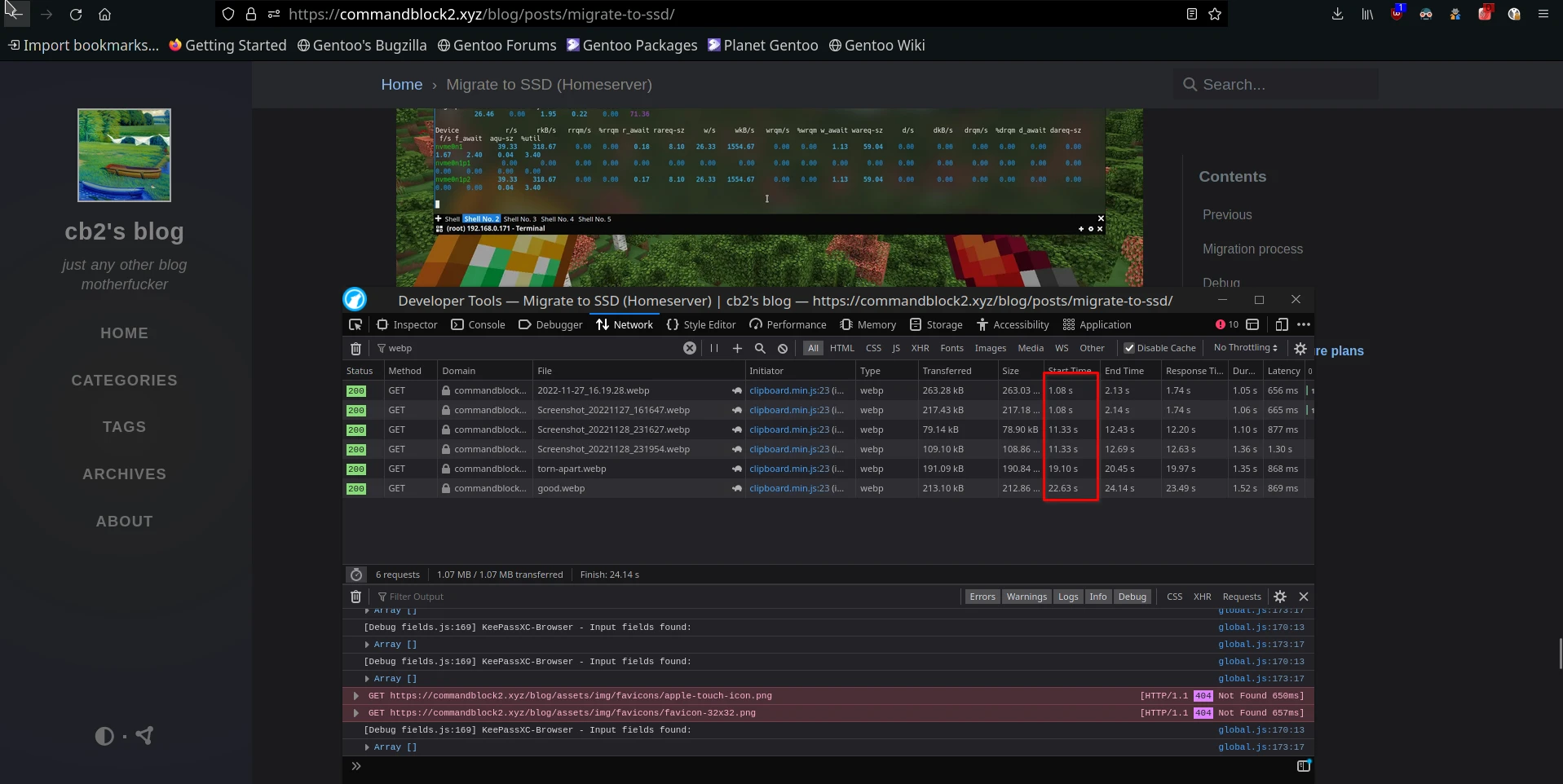 Visible Start Time Difference In Network Tab(dev tools)
Visible Start Time Difference In Network Tab(dev tools)
And I soon realized that it was almost impossible to use wget to automate the process of mirroring my fucking blog.
Resolution
Mirroring such page requires something that is capable of running javascript or I would have to write extra code.
And I then decided to look into other ways.
I was trying to use gayhub CI service for this, I thought, anyway, why do I have to craw the whole site instead of using the site shithub CI built for me already.
So this was done.
1
2
3
4
5
6
7
8
9
10
11
12
13
- name: Build with Jekyll for commandblock2.xyz
run: bundle exec jekyll build --baseurl "/blog"
- name: Pack site
run: tar -czf site.tar.gz _site/*
- name: Remove site built for commandblock2.xyz
run: rm -rf _site/*
- name: Build with Jekyll
# Outputs to the './_site' directory by default
run: bundle exec jekyll build --baseurl "$"
env:
JEKYLL_ENV: production
- name: Put the mirrored site
run: mv ./site.tar.gz _site/
and on my homeserver, an updated.sh is used to fetch and extract the site.tar.gz file periodically.
TODO
See why it still requires js from cdn, I prefer fetching from the homeserver (it doesn’t really matter at that point, except for users of ubo with medium mode at least).
Also make it easier to put images into the blog, or at least some automation in putting the webp screenshot in the image directory.
Why this site is mirrored
I try not to fully rely on github service so that I can easily move away from github anytime I want.
Also this is partially inspired by chinese-independent-blogs-link-rot by yzqzss.
Last, that MOTHERFUCKER is absolutely right.